Open taxonomy
View more presentations from Roderic Page
All the presentations will be posted online, along with podcasts of the audio. Meantime, presentations by Dave Remsen and Chris Freeland are already online.
Lucas N. Joppa, David L. Roberts, Stuart L. Pimm The population ecology and social behaviour of taxonomists Trends in Ecology & Evolution doi:10.1016/j.tree.2011.07.010
Conventional wisdom is highly prejudiced. It suggests that taxonomists were a formerly more numerous people, are in 'crisis', are becoming endangered and are generally asocial. We consider these hypotheses and reject them to varying degrees.
 Two papers estimating the total number of species have recently been published, one in the open access journal PLoS Biology:
Two papers estimating the total number of species have recently been published, one in the open access journal PLoS Biology:Camilo Mora, Derek P. Tittensor, Sina Adl, Alastair G. B. Simpson, Boris Worm. How Many Species Are There on Earth and in the Ocean?. PLoS Biol 9(8): e1001127. doi:10.1371/journal.pbio.1001127

Mark J. Costello, Simon Wilson and Brett Houlding. Predicting total global species richness using rates of species description and estimates of taxonomic effort. Syst Biol (2011) doi:10.1093/sysbio/syr080
Their estimates of ~ 10,000 or so bacteria and archaea on the planet are so completely out of touch in my opinion that this calls into question the validity of their method for bacteria and archaea at all.

| Species | Reference | DOI/PDF | Open Access | |
|---|---|---|---|---|
 | Darwin's Bark Spider | Kuntner, M. and I. Agnarsson. 2010. Web gigantism in Darwin's bark spider, a new species from Madagascar (Araneidae: Caerostris). The Journal of Arachnology 38(2):346-356 | 10.1636/B09-113.1 | No |
 | Bioluminescent Mushroom | Desjardin, D.E., B.A. Perry, D.J. Lodge, C.V. Stevani, and E. Nagasawa. 2010. Luminescent Mycena: new and noteworthy species. Mycologia 102(2):459-477 | 10.3852/09-197 | No |
 | Bacterium | Sanchez-Porro, C., B. Kaur, H. Mann and A. Ventosa. 2010. Halomonas titanicae sp. nov., a halophilic bacterium isolated from the RMS Titanic. International Journal of Systematic and Evolutionary Microbiology 60(12):2768-2774 | 10.1099/ijs.0.020628-0 | No |
 | Monitor Lizard | Welton, L.J., C.D. Siler, D. Bennett, A. Diesmos, M.R. Duya, R. Dugay, E.L.B. Rico, M. van Weerd and R.M. Brown. 2010. A spectacular new Philippine monitor lizard reveals a hidden biogeographic boundary and a novel flagship species for conservation. Biology Letters 6(5):654-658 | 10.1098/rsbl.2010.0119 | No |
 | Pollinating cricket | Hugel, S., C. Micheneau, J. Fournel, B.H. Warren, A. Gauvin-Bialecki, T. Pailler, M.W. Chase and D. Strasberg. 2010. Glomeremus species from the Mascarene islands (Orthoptera, Gryllacrididae) with the description of the pollinator of an endemic orchid from the island of Réunion. Zootaxa 2545:58-68 | No | |
 | Duiker | Colyn, M., J. Hulselmans, G. Sonet, P. Oudé, J. de Winter, A. Natta, Z.T. Nagy and E. Verheyen. 2010. Discovery of a new duiker species (Bovidae: Cephalophinae) from the Dahomey Gap, West Africa. Zootaxa 2637:1-30 | No | |
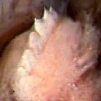 | Leech | Phillips, A.J., R. Arauco-Brown, A. Oceguera-Figueroa, G.P. Gomez, M. Beltran, Y.-T. Lai and M.E. Siddall. 2010. Tyrannobdella rex n. gen. n. sp. and the evolutionary origins of mucosal leech infestations. PLoS ONE 5(4):e10057 | 10.1371/journal.pone.0010057 | Yes |
 | Underwater mushroom | Frank, J.L., R.A. Coffan and D. Southworth. 2010. Aquatic gilled mushrooms: Psathyrella fruiting in the Rogue River in southern Oregon. Mycologia 102(1):93-107 | 10.3852/07-190 | No |
 | Jumping cockroach | Bohn, H., M. Picker, K.-D. Klass and J. Colville. 2010. A jumping cockroach from South Africa, Saltoblattella montistabularis, gen. nov., spec. nov. (Blattodea: Blattellidae). Arthropod Systematics and Phylogeny 68(1):53-39/td> | Yes | |
 | Pancake Batfish | Ho, H.-C., P. Chakrabarty and J.S. Sparks. 2010. Review of the Halieutichthys aculeatus species complex (Lophiiformes: Ogcocephalidae), with descriptions of two new species. Journal of Fish Biology 77(4):841-869 | 10.1111/j.1095-8649.2010.02716.x | No |
&mindate=2010/12/01 and &maxdate=2010-12-31 to form this URL:&retmax to a big number to ensure I get all the tax_ids for that month (in this case 23511). I then made a local copy of the NCBI database in MySQL ( instructions here) and queried for all species-level taxa in GenBank. I used a rather crude regular expression REGEXP '^[A-Z][a-z]+ [a-z][a-z]+$' to find just those species names that were likely to be proper scientific names (i.e., no "sp.", "aff.", museum or voucher codes, etc.). To group the species into major taxonomic groups I used the division_id. http://iphylo.org/linkout/<TreeBase taxon identifier>, e.g. http://iphylo.org/linkout/TB2:Tl257333. This page simply gives the name of the taxon in TreeBASE and the corresponding NCBI taxon id. It uses a Semantic Mediawiki template to generate a statement that the TreeBASE and and NCBI taxa are a "close match". If you go to the corresponding page in the wiki for the NCBI taxon (e.g., http://iphylo.org/linkout/Ncbi:448631) you will see any corresponding TreeBASE taxa listed there. If a mapping is erroneous, we simply need to edit the TreeBASE taxon page in the wiki to fix it. Nice and simple. Those who seek answers to big, broad questions about biology, especially questions emphasizing the organism (taxonomy, evolution and ecology), will soon benefit from an emerging names-based infrastructure. It will draw on the almost universal association of organism names with biological information to index and interconnect information distributed across the Internet. The result will be a virtual data commons, expanding as further data are shared, allowing biology to become more of a ‘big science’. Informatics devices will exploit this ‘big new biology’, revitalizing comparative biology with a broad perspective to reveal previously inaccessible trends and discontinuities, so helping us to reveal unfamiliar biological truths. Here, we review the first components of this freely available, participatory and semantic Global Names Architecture.Do we need names?
Surrogates include provisional names and specimen, culture or strain numbers which refer to a taxon. 'SAR-11' ('SAR' refers to the Sargasso Sea) was a surrogate name given in 1990 to an important member of the marine plankton. Only a decade later did it become known as Pelagibacter ubique.

 Taxonomy
Taxonomy
